들어가며
최근 코루틴을 오랜만에 다시, 그러나 제대로 공부해보았습니다.
사실 공부를 제대로 시작하기 전까지는 코루틴 사용 방법과 주요 특징만 제대로 알고 있었고, 정확한 내부 동작은 잘 이해하지 못했습니다. 코루틴에 관한 책도 발췌독으로 읽으며 그때그때 필요한 내용을 살펴보기만 했었는데요.
다시 취준을 하다보니 코루틴을 제대로 파헤쳐보아야겠다는 생각이 뒤늦게 들었습니다. 그래서 그렇게 미루고 미루던 코루틴 시리즈를 시작해보려합니다.
코루틴 시리즈의 글은 “코틀린 코루틴의 정석” 책을 바탕으로 하며, 개인적으로 더 공부하거나 찾아본 내용으로 구성될 예정입니다.
코루틴이 좋다고들 하지만, 왜 좋은걸까요? 어떤 기술이 왜 좋은가를 이해하기 위해서는 이전의 방식이 어떤 문제점이 있었는가를 살펴보면 도움이 됩니다. 이번 포스팅에서는 멀티 스레드와 비교하여 코루틴이 좋은 이유를 이해하고자 스레드를 활용한 방식의 특징과 단점을 먼저 알아보겠습니다.
이 글을 읽기 전…
- 스레드와 프로세스에 관한 개념을 알고 계시면 좋습니다.
- 동시성과 병렬성의 개념을 이해하고 계시면 좋습니다.
- 스레드를 이용한 동기 및 비동기 처리를 잘 알고계시면 좋습니다.
스레드 살펴보기
사실 코루틴에 관한 이야기를 시작하려면 스레드와 동시성, 병렬성, 비동기에 관한 이야기를 빼놓을 수 없습니다. 그러나 이 내용을 모두 다룬다면 코루틴 시리즈는 몇 달간 시작도 할 수 없을 것이기에, 스레드에 관해서만 짧게 짚어보겠습니다.
스레드
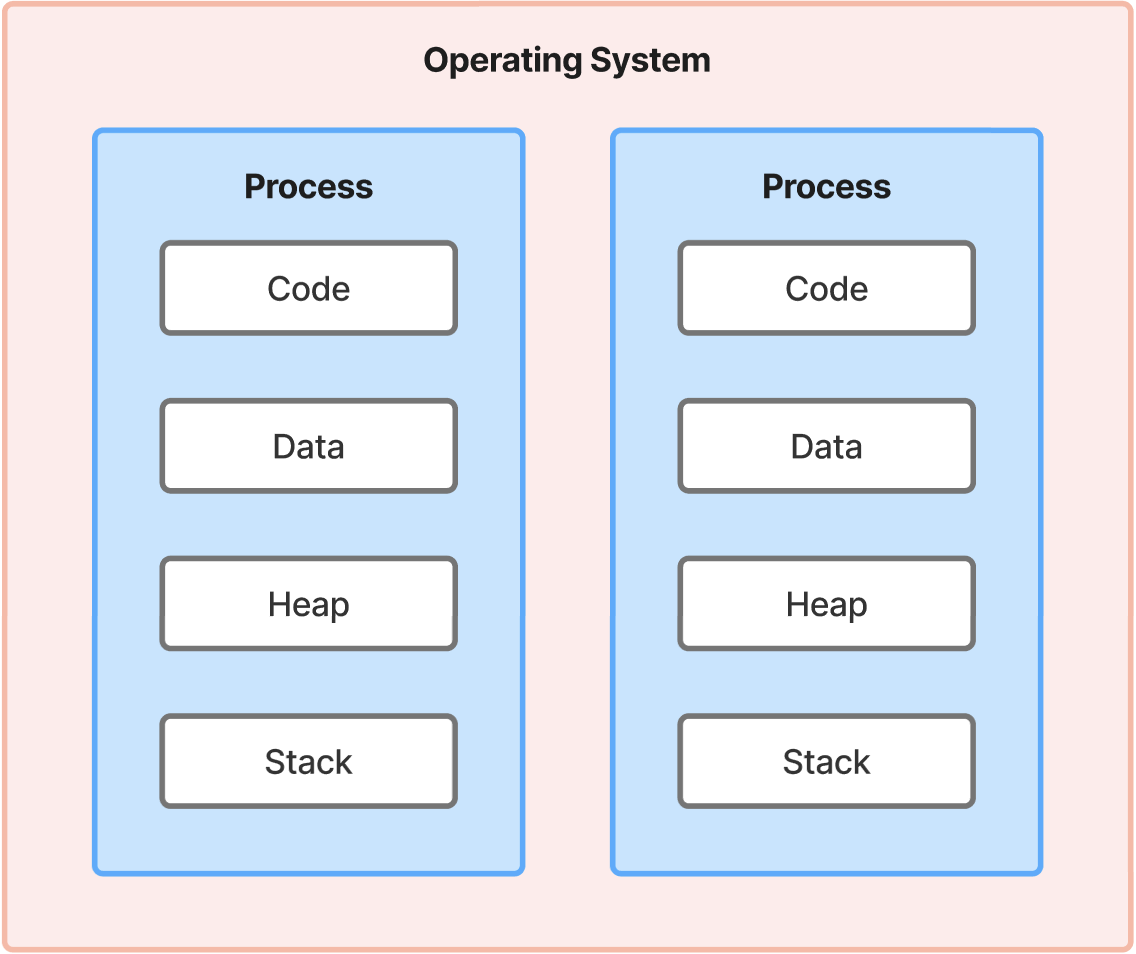
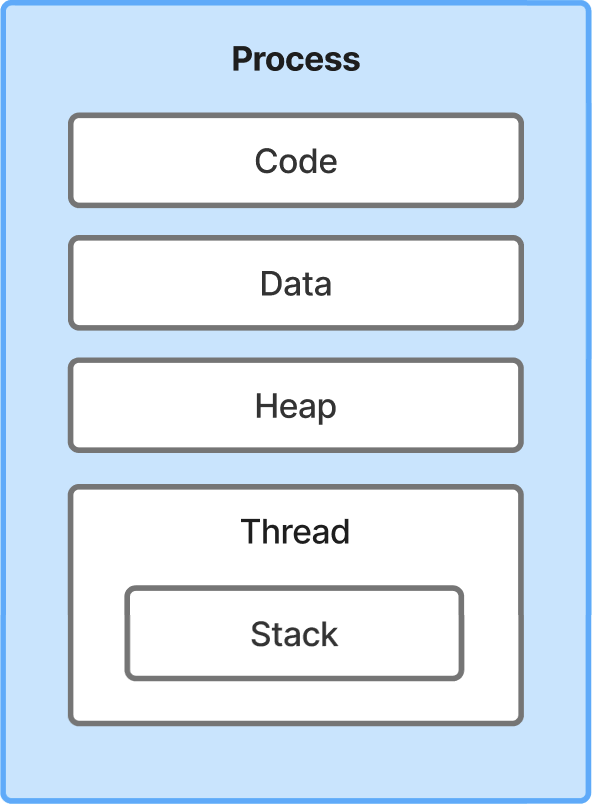
스레드는 프로세스 안에서 실행하는 기본적인 작업 단위입니다. 이 작업은 하나일 수도 있고, 여러 개가 될 수도 있습니다. 또한 동일 프로세스 안에서 실행되는 스레드는 프로세스의 데이터, 힙 메모리 공간을 공유하기 때문에 공유 자원에 접근할 수 있습니다.

- 프로세스는 스레드를 생성해 작업을 처리합니다.
- 그리고 다수의 스레드를 이용해서 여러 작업을 동시에, 또는 비동기적으로 처리할 수 있습니다.
- 스레드는 하나의 작업을 수행할 때 다른 작업을 동시에 수행할 수 없습니다.
멀티 스레드 프로그래밍
단일 스레드의 한계와 멀티 스레드 프로그래밍
단일 스레드 프로세스의 한계
프로세스에서 최초로 실행되어 기본적인 실행 흐름을 가져가는 스레드를 메인 스레드라 합니다. 하나의 스레드 만으로 실행되는 프로세스는 이 처음 실행된 메인 스레드에서 모든 작업을 수행합니다.
앞서 스레드는 하나의 작업을 수행할 때 다른 작업을 동시에 수행하지 못한다고 설명했습니다. 스레드에서 하나의 작업을 수행 중이라면, 해당 작업이 처리되는 동안 스레드는 다른 작업을 수행하지 못합니다. 이를 스레드의 점유라고 부릅니다. 그래서 만약 메인 스레드에서만 작업을 처리하는 단일 스레드 프로세스가 오래 걸리는 작업을 하고 있다면, 그동안 다른 작업들은 그 작업이 끝날 때까지 대기해야합니다.

물론, 단일 스레드 작업 처리 방식 자체가 문제가 되는 것은 절대 아닙니다. 하지만 작업의 응답성을 낮추어 프로그램의 성능이 저하될 수 있는 요인이 되기도 합니다.

단일 스레드를 사용하는 안드로이드 앱이 있다고 가정해봅시다. 안드로이드 앱이 메인 스레드 하나만을 사용한다면, 네트워크 작업과 같은 오래 걸리는 작업이 완료될 때까지 메인 스레드가 차단되어 안드로이드 앱은 UI를 그리는 작업을 멈추게 됩니다. 만약 메인 스레드가 오랫동안 차단되면 ANR(Application Not Responding) 오류가 발생하고, 안드로이드 시스템은 경고를 띄워 앱을 종료할지 대기할지 묻습니다.
이렇게 앱이 응답하지 않고 멈추는 현상은 사용자로 하여금 불만족스러운 사용 경험을 제공할 수 있기 때문에 발생하지 않도록 주의해야 합니다.
멀티 스레드 프로그래밍 : 단일 스레드의 한계 극복
이런 단일 스레드의 한계를 극복하기 위한 방법으로 멀티 스레드 프로그래밍을 활용할 수 있습니다.
멀티 스레드 프로그래밍이란 여러 개의 스레드를 사용해 작업을 처리하는 프로그래밍 기법입니다. 각각의 스레드가 한 번에 하나의 작업을 처리할 수 있으므로 여러 작업을 동시에 처리하는 것이 가능해집니다.

안드로이드 앱의 메인 스레드에서 오래 걸리는 작업이 요청됐을 때 이를 백그라운드에서 처리하도록 만들면, 메인 스레드는 오래 걸리는 작업을 하지 않아도 되기 때문에 UI가 멈추거나 사용자 입력을 받지 못하는 현상을 방지할 수 있습니다.

이렇듯 여러 스레드에서 동시에 작업을 처리하는 방식을 병렬 처리라고 부릅니다.
모든 작업을 작은 단위로 나눠서 병렬로 실행할 수 있는 것은 아닙니다. 작은 작업 간에 독립성이 있을 때만 병렬로 실행할 수 있습니다. 만약 큰 작업을 작은 작업으로 분할했을 때, 이들 작업이 독립적이지 않고 작업 간에 의존성이 있다면 작은 작업을 순차적으로 실행해야 합니다.
스레드와 스레드풀을 사용한 멀티스레드 프로그래밍
Thread 클래스 활용하는 방법
자바와 코틀린에서는 Thread를 상속하는 클래스를 만들어 오래 걸리는 작업을 별도로 실행시킬 수 있습니다.
class ExampleThread : Thread() {
override fun run() {
println("[${Thread.currentThread().name}] 새로운 스레드 시작")
Thread.sleep(2000L) // 2초 동안 대기
println("[${Thread.currentThread().name}] 새로운 스레드 종료")
}
}
이 스레드를 main에서 실행시킵니다.
fun main() {
println("[${Thread.currentThread().name}] 메인 스레드 시작")
ExampleThread().start()
Thread.sleep(100OL) // 1초동안 대기
println("[${Thread.currentThread().name}] 메인 스레드 종료")
}
/*
// 결과:
[main] 메인 스레드 시작
[Thread-0] 새로운 스레드 시작
[main] 메인 스레드 종료
[Thread-0] 새로운 스레드 종료
*/
하지만 이 방법은 두 가지 문제점이 있습니다.
- 스레드는 생성 비용이 비싸기 때문에 매번 새로운 스레드를 생성하는 것은 성능적으로 좋지 않습니다.
- 스레드 생성과 관리에 대한 책임이 개발자에게 있습니다. 따라서 프로그램의 복잡성이 증가하며, 실수로 인해 오류나 메모리 누수를 일으킬 가능성이 있습니다.
이 문제를 해결하려면 생성한 스레드를 간편하게 재사용할 수 있어야 하고, 스레드 관리를 미리 구축한 시스템에서 책임지도록 해야합니다. 이런 문제점을 해결하기 위해 Executor 프레임워크가 등장했습니다.
Executor 프레임워크를 통해 스레드풀 사용하기
Executor 프레임워크는 개발자가 아닌 프레임워크가 스레드를 관리, 생성된 스레드의 재사용성을 높이기 위해 등장했습니다. 스레드풀을 관리하고 사용자로부터 요청받은 작업을 각 스레드에 할당하는 시스템을 더한 것이 바로 Executor 프레임워크입니다.
스레드풀(Thread Pool) : 스레드의 집합
Executor 프레임워크는 스레드풀을 미리 생성해놓고, 작업 요청을 받으면 쉬고 있는 스레드에 작업을 분배합니다. 스레드가 작업을 끝내더라도 스레드를 종료하지 않고 다음 작업이 들어오면 재사용합니다.
스레드풀에 속한 스레드 생성, 관리, 작업 분배에 대한 책임을 Executor 프레임워크가 담당하므로, 개발자는 이에 대한 책임이 줄어듭니다. 개발자가 할 일은 스레드풀에 속한 스레드 개수를 설정하고, 이를 관리하는 서비스에 작업을 제출하는 것 뿐이죠.
코루틴을 사용하기 전에는 Executor와 같은 프레임워크를 통해 스레드풀을 생성하고 스레드에 작업을 할당하는 방식으로 비동기 작업을 처리했습니다.
Executor 프레임워크 사용 방법
1. ExecutorService 생성
val executorService: ExecutorService = Executors.newFixedThreadPool(2)
2. submit 메서드를 통해 스레드풀에 작업을 제출
fun main() {
val startTime = System.currentTimeMillis()
// ExecutorService 생성
val executorService: ExecutorService = Executors.newFixedThreadPool(2)
// 작업 1 제출
executorService.submit {
println("[${Thread.currentThread().name}][${getElapsedTime(startTime)}] 작업 1 시작")
Thread.sleep(1000L)// 1 초간 대기
println("[${Thread.currentThread().name}][${getElapsedTime(startTine)}] 작업 1 완료")
}
// 작업 2 제출
executorService.submit {
printIn("[${Thread.currentThread().name}][${getElapsedTime(startTime)}] 작업 2 시작")
Thread.sleep(1000L)// 1 초간 대기
printIn("[${Thread.currentThread().name}][${getElapsedTime(startTime)}] 작업 2 완료")
}
// 작업 3 제출
executorService.submit {
printIn("[${Thread.currentThread().name}][${getElapsedTime(startTime)}] 작업 3 시작")
Thread.sleep(1000L)// 1 초간 대기
printIn("[${Thread.currentThread().name}][${getElapsedTime(startTime)}] 작업 3 완료")
}
executorService.shutdown()
}
fun getElapsedTime(startTime: Long): String = "지난 시간: ${System.currentTimeMillis() - startTime}ms"실행 결과 : 서로 다른 스레드에서 실행되기 때문에 출력 순서, 사용 스레드는 다를 수 있습니다.
[pool-1-thread-1][지난 시간: 4ms] 작업 1 시작
[pool-1-thread-2][지난 시간: 4ms] 작업 2 시작
[pool-1-thread-1][지난 시간: 1009ms] 작업 1 완료
[pool-1-thread-2][지난 시간: 1011ms] 작업 2 완료
[pool-1-thread-1][지난 시간: 1012ms] 작업 3 시작
[pool-1-thread-1][지난 시간: 2016ms] 작업 3 완료
위 예제에서 알 수 있듯, 스레드풀을 생성하고 여기에 작업을 전달하기 위해 ExecutorService 객체를 사용합니다.
ExecutorService 객체는 크게 아래 두 요소로 구성되어 있습니다.
- BlockingQueue: 작업 대기열, 할당 받은 작업을 적재
- ThreadPool: 스레드풀, 작업을 수행하는 스레드의 집합
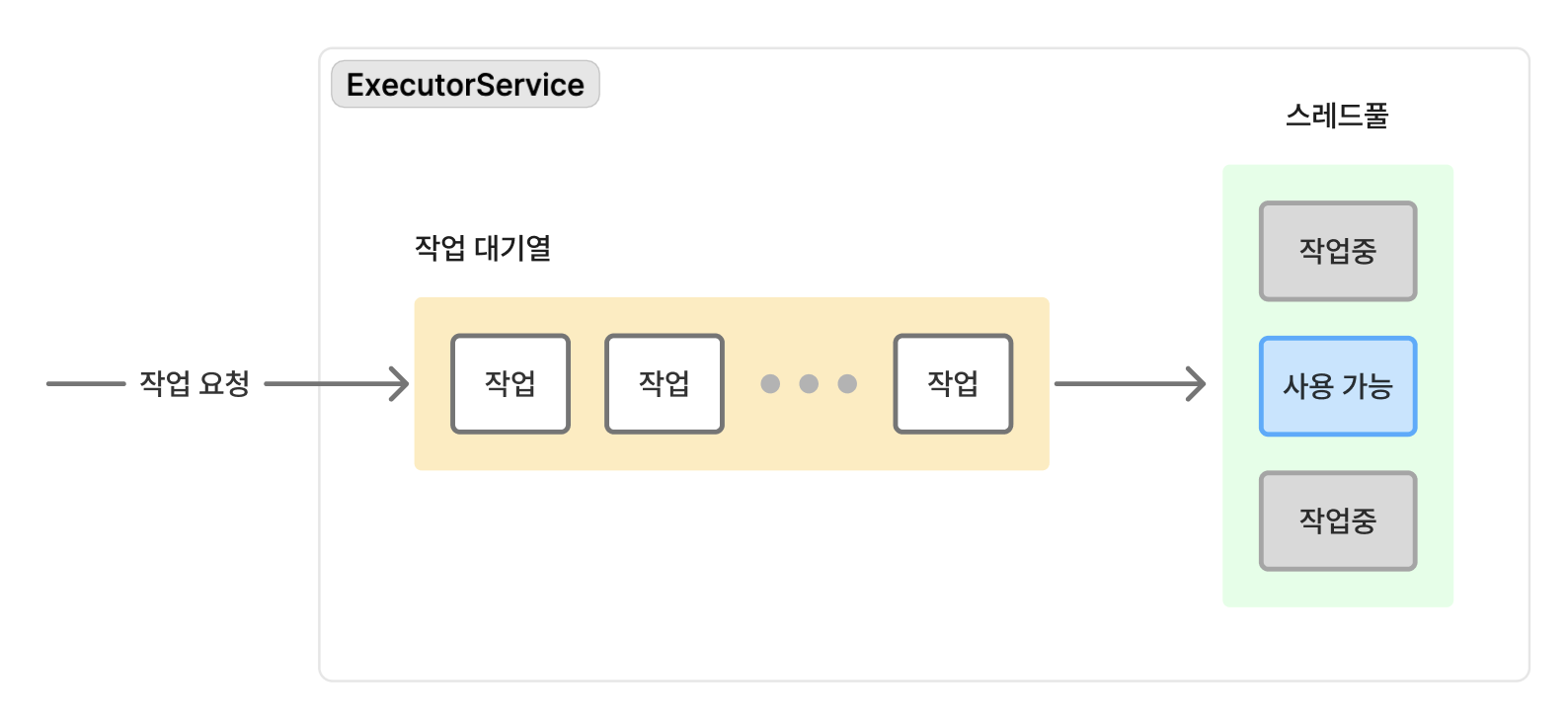
ExecutorService 객체는 사용자로부터 요청 받은 작업을 작업 대기열에 적재한 후, 놀고 있는 스레드에 작업을 할당합니다.
스레드와 코루틴
기존 멀티 스레드 프로그래밍의 한계
이러한 멀티 스레드 프로그래밍은 계속해서 여러 사용성이나 기존에 존재하던 단점들을 보완하고 발전해왔습니다.
그럼에도 여전히 문제점이 존재했습니다. 바로 스레드 블로킹을 해결하지 못한 것입니다. 기본적으로 스레드 프로그래밍은 스레드 기반으로 작업한다는 한계를 가지고 있습니다.
오잉? 단일 스레드의 문제점을 멀티 스레드로 해결했는데, 오히려 스레드를 사용하는게 문제라구요?
스레드 블로킹이란?
앞서 스레드의 가장 큰 특징이 하나의 작업을 수행할 때 다른 작업을 동시에 수행하지 못한다는 것이라고 설명한 것을 기억하시나요?
이런 특징으로 인해 스레드 블로킹이라는 현상이 발생하고, 이것이 멀티 스레드 프로그래밍의 근본적인 문제점입니다.
스레드 블로킹(Thread Blocking) : 하나의 스레드가 다른 스레드에서 수행하는 작업이 완료될 때까지 사용할 수 없는 상태에 놓이는 것
스레드 블로킹이 발생하면 스레드는 아무것도 하지 못하고, 이 스레드를 사용할 수도 없습니다.
스레드는 비싼 자원입니다. 생성에 비교적 큰 비용이 발생하고, 스레드를 오가며 작업을 처리하며 발생하는 컨텍스트 스위칭의 비용도 무시할 수 없습니다. 때문에 스레드가 사용될 수 없는 상태에 놓이는 것이 반복되면 결국 애플리케이션 성능 저하로 이어집니다.
스레드 블로킹의 발생 원인
스레드 블로킹의 발생 원인은 여러 가지가 있습니다.
- 여러 스레드가 동기화 블록에 동시 접근하는 경우
- Mutex, Semaphore로 인해 공유 자원에 접근할 수 있는 스레드가 제한되는 경우
- 하나의 스레드만이 동기화 블록에 접근하는 것이 허용되기 때문에, 다른 스레드는 Block 됩니다.
- 다른 스레드에서의 작업 결과가 필요한 경우
- 특정 스레드가 작업을 계속 이어가려할 때, 다른 스레드에서 수행한 작업 결과가 필요하게 될 수 있습니다.
- 대표적인 예시로 네트워크 요청에 대한 결과를 UI에 보여줘야한다면, UI를 그리던 메인 스레드는 서버에서 데이터가 전달될 때까지 작업을 중단해야 합니다.
- Executor 프레임워크 예시: ExecutorService 객체에 제출한 작업에서 결과를 전달받을 때는 언제 올지 모르는 값을 기다리는 데 Future 객체를 사용(get 호출) → get 함수를 호출한 스레드가 결과값이 반환될 때까지 블로킹
간단한 콜백이나 체이닝 함수 등의 방법을 사용하면 스레드 블로킹을 피할 수 있습니다. 그러나 작업이 많아지고 작업 간 종속성이 복잡해질수록 스레드 블로킹을 피하기 어렵고, 만들어진 스레드가 성능을 제대로 발휘하지 못하는 경우가 자주 발생합니다.
체이닝 함수: 한 함수의 결과를 바로 다른 함수로 연결해 호출하는데 사용, 즉 함수가 실행 완료됐을 때 실행할 콜백을 등록하는 것
그래서 등장한 코루틴!
멀티 스레드 프로그래밍의 문제점을 해결하기 위해 코루틴(Coroutine)이라는 개념이 등장했습니다.
코루틴은 작업 단위 코루틴을 통해 스레드 블로킹 문제를 해결합니다.
작업 단위 코루틴 : 스레드에서 작업 실행 도중 일시 중단할 수 있는 작업 단위
코루틴의 대표적인 특징은 다음과 같습니다.
- 작업을 원하는 시점에 일시 중단(suspend)할 수 있습니다. 작업이 일시 중단되면 더 이상 스레드 사용이 필요하지 않습니다.
- 스레드를 사용하지 않으면 스레드 사용 권한을 양보합니다. 양보된 스레드는 다른 코루틴 작업을 실행하는데 사용될 수 있습니다.
- 일시 중단된 코루틴은 재개 시점에 다시 스레드에 할당돼 실행됩니다. 이 때 스레드풀 내의 다른 사용 가능한 스레드에서 작업을 재개합니다.
- 이러한 원리로 스레드의 효율성을 높입니다. 마치 코루틴 간에 서로 협력하듯이 움직입니다.
코루틴의 동작 방식
코루틴이 동작하는 흐름을 간단히 살펴보겠습니다.
- 프로그래머가 코루틴을 만들어 코루틴 스케줄러에 넘깁니다.
- 코루틴 스케줄러는 자신이 사용할 수 있는 스레드나 스레드풀에 해당 코루틴을 분배해 작업을 수행합니다.
- 코루틴이 스레드 사용 중 필요가 없어지면 해당 스레드를 다른 코루틴이 쓸 수 있게 양보할 수 있습니다. 즉, 스레드 블로킹이 일어나지 않습니다.
이러한 동작 방식은 마치 스레드에 코루틴이라는 작업을 원하는 시점에 떼었다, 붙였다 할 수 있는 것과 같습니다.
코루틴이 경량 스레드라고 불리는 이유
일반적으로 코루틴을 경량 스레드라고도 표현합니다.
코루틴은 스레드 위에서 실행되는 하나의 작은 작업 단위입니다. 스레드를 사용하지 않을 때에는 스레드 사용 권한을 양보하여 스레드 사용을 최적화하고 스레드가 블로킹되는 상황을 방지합니다.
또한 스레드에 비해 생성 비용이 적고, 스레드에 자유롭게 뗐다 붙였다 할 수 있습니다. 그래서 작업 생성과 전환에 필요한 리소스와 시간 절약할 수 있죠.
스레드 위에서 동작하고 멀티 스레드 프로그래밍으로 여러 작업을 처리하는 개념은 동일하지만, 스레드에 비해 발생하는 비용이 적고 최적화된 스레드 사용이 가능하기 때문에 경량 스레드, 가벼운 스레드라고 비유하는 것입니다.
미리 살펴보는 코루틴의 장점
- 스레드를 쓰지 않을 때 사용 권한을 양보 → 스레드 사용 최적화 및 블로킹 방지
- 스레드에 비해 작업 생성과 전환에 대한 비용이 적음
- 구조화된 동시성을 통해 비동기 작업을 안전하게 만들고 예외 처리를 효과적으로 처리할 수 있다
- 코루틴이 실행 중인 스레드를 손쉽게 전환 가능
마치며
멀티 스레드 프로그래밍과 코루틴의 차이점을 살펴보며 코루틴의 개념과 코루틴의 장점에 대해 알아보았습니다.
코루틴 시리즈의 다음 포스트는 코루틴 디스패처(CoroutineDispatcher)를 학습해보겠습니다.
[Kotlin] CoroutineDispatcher란?
들어가며해당 글은 도서 을 기반으로 코루틴에 대해 학습하는 시리즈의 글입니다. 코틀린 코루틴 시리즈의 이전 글[Kotlin] 멀티 스레드와 코루틴 [Kotlin] 멀티 스레드와 코루틴들어가며최근 코루
walnut-dev.tistory.com
'개발 > Kotlin' 카테고리의 다른 글
| [Kotlin] CoroutineDispatcher란? (0) | 2025.11.17 |
|---|